Come funziona un database relazionale
Nel vasto universo dell’informatica, i database relazionali rappresentano una delle pietre angolari della gestione dei dati. Immaginate un enorme archivio, organizzato con cura e in grado di custodire informazioni preziose, pronte a essere evocate con un semplice comando. Ma come funziona realmente un database relazionale? In questo articolo, ci addentreremo nel cuore pulsante di queste strutture dati, esplorando i principi fondamentali che ne regolano il funzionamento e scoprendo come l’interazione tra tabelle, relazioni e query permetta di trasformare i dati in conoscenza utile e comprensibile. Attraverso un viaggio affascinante e accessibile,sveleremo i meccanismi che animano questi sistemi,permettendo così a tutti di comprendere l’importanza e l’efficacia dei database relazionali nel mondo moderno.
La struttura dei dati e le relazioni tra tabelle nei database relazionali
Nei database relazionali, la struttura dei dati è fondamentale per garantire l’integrità e l’efficienza nella gestione delle informazioni. Ogni database è composto da una serie di tabelle, ognuna delle quali rappresenta un’entità specifica, come clienti, prodotti o ordini. Le tabelle sono organizzate in righe e colonne,dove le righe corrispondono ai record e le colonne agli attributi di ciascun record. Ad esempio, in una tabella dei clienti, ogni riga potrebbe contenere informazioni relative a un singolo cliente, come nome, indirizzo e numero di telefono, mentre le colonne rappresenterebbero le diverse informazioni.
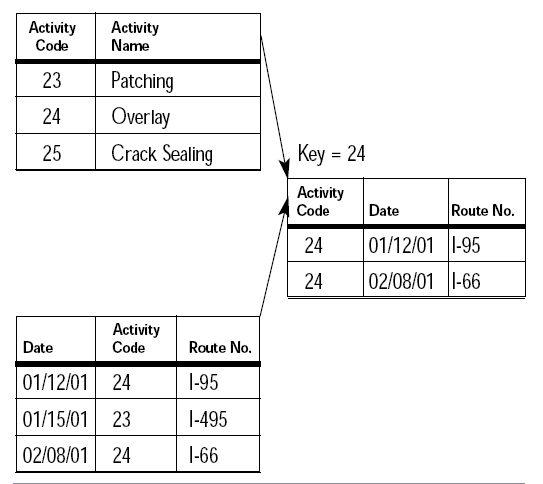
Le relazioni tra le tabelle sono essenziali per creare un sistema coeso e interconnesso. Esistono principalmente tre tipi di relazioni: una a uno, una a molti e molti a molti. Nella relazione uno a uno, un record in una tabella è collegato a un singolo record in un’altra tabella. Ad esempio, ogni cliente potrebbe avere un solo account di accesso. Nella relazione uno a molti, un record di una tabella può essere associato a più record in un’altra tabella. Questo è il caso di un cliente che ha effettuato più ordini. nella relazione molti a molti, più record in una tabella sono collegati a più record in un’altra tabella, come nel caso di studenti e corsi, dove uno studente può iscriversi a più corsi e ciascun corso può avere più studenti.
Le chiavi primarie e le chiavi esterne giocano un ruolo cruciale nella definizione di queste relazioni. Una chiave primaria è un attributo univoco che identifica un record all’interno di una tabella. Ad esempio, il numero identificativo di un cliente potrebbe fungere da chiave primaria. D’altra parte, una chiave esterna è un attributo in una tabella che fa riferimento alla chiave primaria di un’altra tabella. Utilizzando le chiavi esterne, è possibile creare collegamenti tra le tabelle, facilitando la navigazione e l’interrogazione dei dati. Le chiavi esterne non solo connettono i dati, ma aiutano anche a mantenere l’integrità referenziale, assicurando che le relazioni siano coerenti e valide.
Una comprensione approfondita delle relazioni tra tabelle è fondamentale per la progettazione di un database efficiente. Quando si creano tabelle, è importante considerare come i dati interagiranno. Ad esempio,se si prevede di implementare una relazione uno a molti tra clienti e ordini,la tabella degli ordini dovrebbe contenere una colonna per la chiave esterna del cliente. Questo garantisce che ogni ordine possa essere facilmente associato al cliente corrispondente, evitando la ridondanza e migliorando l’organizzazione dei dati.
La normalizzazione è una tecnica utilizzata per ottimizzare la struttura dei dati e le relazioni tra tabelle. Questo processo implica la suddivisione delle tabelle in sotto-tabelle più piccole e la rimozione di dati ridondanti. Esistono diverse forme normali, ognuna con requisiti specifici per garantire che la struttura dei dati sia ottimale. ad esempio, la prima forma normale richiede che tutte le colonne contengano dati atomici, mentre la seconda forma normale mette in evidenza l’importanza di avere chiavi primarie per ogni tabella. La normalizzazione aiuta a semplificare la gestione e l’interrogazione dei dati, rendendo il database più efficiente.
Al contrario, in alcuni casi può essere utile denormalizzare il database. Questo significa unire tabelle o mantenere dati ridondanti per migliorare le prestazioni delle interrogazioni, soprattutto in scenari ad alta capacità di accesso, dove le prestazioni possono essere compromesse dalla complessità delle relazioni. Tuttavia, è importante trovare un equilibrio tra normalizzazione e denormalizzazione, poiché un’eccessiva ridondanza può portare a consistenza dei dati inaffidabile.
Le interrogazioni sui database relazionali sfruttano la struttura dei dati e le relazioni per recuperare informazioni integrate in modo efficiente. Attraverso il linguaggio SQL (Structured Query Language), è possibile eseguire interrogazioni che attingono a più tabelle contemporaneamente. Utilizzando comandi come JOIN, è possibile combinare dati da diverse tabelle in un’unica vista coerente.Ad esempio, per recuperare tutti gli ordini effettuati da un cliente specifico, si può unire la tabella dei clienti con la tabella degli ordini, facilitando l’analisi delle informazioni.la gestione delle relazioni tra tabelle non è solo una questione tecnica, ma anche strategica.Pianificare correttamente la struttura dei dati e le relazioni consente alle aziende di ottenere insight preziosi e di prendere decisioni informate. Sia che si tratti di migliorare l’efficienza operativa o di personalizzare l’esperienza del cliente, avere una solida architettura dei dati è fondamentale per il successo a lungo termine in un mondo guidato dai dati.





Lascia un commento